
Questo articolo fa parte di una serie di mie riflessioni sull’innovazione technology-driven, cominciata qui.
Possiamo dire che i Big Data sono una nuova generazione di tecnologie ed architetture, destinate ad estrarre valore economico da volumi di dati molto grandi, di grande varietà, abilitando una loro veloce cattura, analisi e fruizione.
Quindi con Big Data identifichiamo un cambiamento nel modo in cui consumiamo, processiamo e applichiamo le informazioni per creare conoscenza.
È un approccio per
- sfruttare molteplici fonti di dati per far emergere conoscenza che rimane «nascosta» alle analisi dati tradizionali
- utilizzando, fra l’altro, i social media, l’analisi di testi in linguaggio naturale e schemi di dati dinamici e flessibili
- e spesso «aggirando» strumenti, processi e policy tradizionali per accelerare l’ottenimento dei risultati
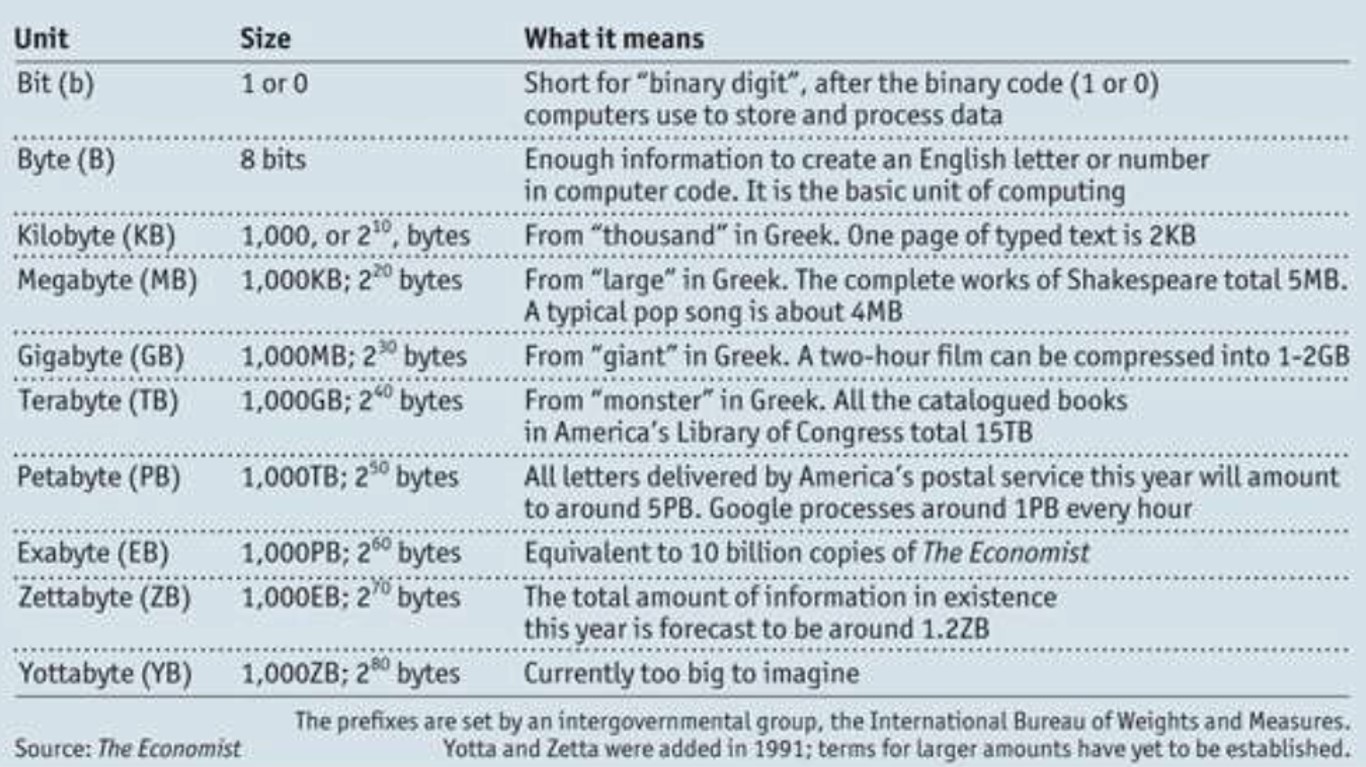
Questo schema vi da un’idea dei volumi di dati di cui stiamo parlando e della relativa terminologia. Dicevamo che un exabyte equivale a 10 miliardi di copie dell’economist (da cui ho preso la tabella), che lo Zettabyte è la misura di tutte le informazioni prodotte, nel mondo, in un anno, mentre per lo Yottabyte ancora non possiamo immaginare un metro di paragone.
Possiamo anche dire (ed è molto utile) con Non sono i Big Data.
Abbiamo visto che non sono un’idea nuova e soprattutto non generano automaticamente nuova conoscenza: occorre una fase importante di «distillazione».
Non sono (generalmente) utilizzati per decisioni di tipo real time.
E quello che è più importante per chi approccia un progetto sui Big Data, c’è ancora relativa incertezza sugli standard di riferimento e sicuramente gli investimenti necessari sono rilevanti (i Big Data non sono a buon mercato)
