
Questo articolo fa parte di una serie di mie riflessioni sull’innovazione technology-driven, cominciata qui.
Secondo il Big Data Working Group del NIST (NBD-WG) ed in particolare l’architetto G. Mazzaferro di AlloyCloud, le applicazioni costruite a partire dai Big Data possono avere modelli operativi molto differenti, in funzione del loro ruolo, che può essere strategico (di medio-lungo periodo), tattico (di breve periodo) o time sensitive (contingente).
Per i diversi profili applicativi, diversa è la combinazione di alcune caratteristiche chiave dei dati, fra cui le tre Vs.

Per applicazioni di tipo strategico, in cui l’analisi inferenziale dei dati è al servizio della definizione e verifica della mission aziendale, di campagne di riposizionamento del brand, … si utilizzano dati con maggiore confidenza e maggiore varietà, con minore velocità di cattura e manipolazione, derivati da fonti differenziate e «cotti», cioè con maggiore elaborazione intermedia. Tipicamente il costo di sviluppo e gestione di un’applicazione di questa natura è pre-determinato.
All’estremo opposto, le applicazioni time sensitive sono quelle in cui la risposta dev’essere immediata (pensate ad esempio ad Amazon che vi dice quali altri libri scegliere in funzione di quello che avete appena acquistato). In questo tipo di applicazioni si può accettare una confidenza minore nei dati, che vengono acquisiti da poche fonti, con caratteristiche di sensori (cioè fonti che ci dicono cosa sta accadendo in questo istante), poco differenziate e tipicamente i dati si utilizzano «crudi», senza molte elaborazioni intermedie. Il costo di queste applicazioni è molto variabile, anche in funzione del fatto che la loro availability deve essere molto alta.
In mezzo ci sono ovviamente varie combinazioni, per applicazioni orientate a pianificazioni di breve periodo o a risposte in tempo breve, ma non immediate.
Lo schema seguente illustra i ruoli organizzativi coinvolti nello sviluppo e gestione di un’applicazione di tipo Big Data.
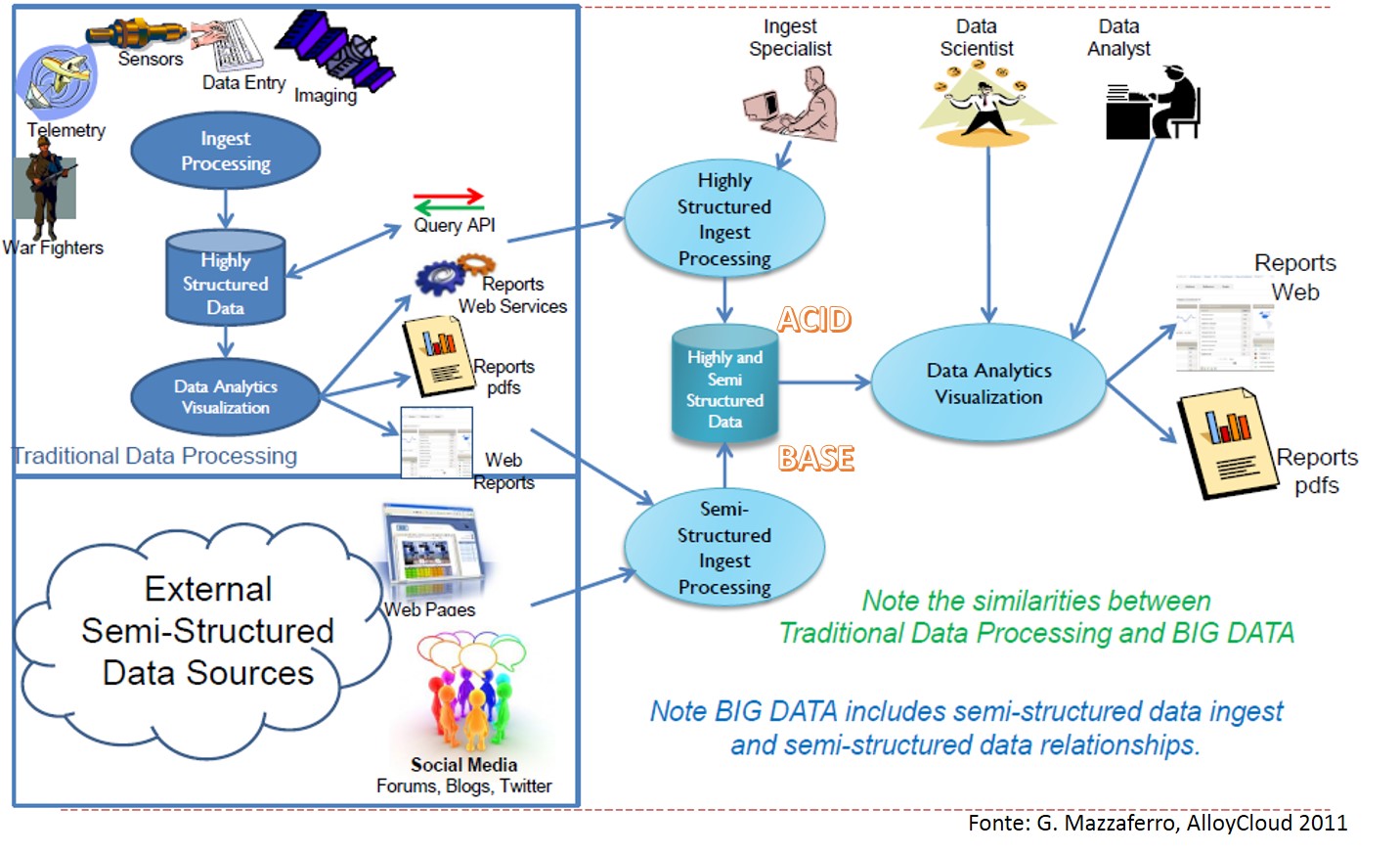
È interessante notare che in alto a sinistra ritroviamo i ruoli tipici di un processo tradizionale di business intelligence:
- fonti di dati
- processo di acquisizione dei dati, che trasforma i dati inseriti in una base dati altamente strutturata (tipicamente RDBMS)
- alla quale possono accedere altre applicazioni tramite linguaggi di tipo SQL o Application Programming Interface
- o uno strumento standardizzato di analisi e reporting, che produce report per diversi media e diversi ruoli aziendali.
A questo ambiente di gestione tradizionale dei dati, si affianca un ambiente (in basso a sinistra) di gestione di dati non strutturati, che possono essere dati di tipo documentale, pagine web, dati da social media, o anche output del processo tradizionale di data processing.
Su questi dati, interviene una nuova figura di specialista dell’acquisizione dei dati, che seleziona e manipola i dati perché possano essere rappresentati e correlati in un’unica base dati, in cui spesso le componenti relazionali e le componenti NoSQL sono complementari.
Sulla base dati lavorano i cosiddetti Data Scientists, tipicamente risorse con skill molto avanzati di tipo statistico e data mining, che sviluppano i modelli di natura inferenziale e i cosiddetti Data Analists, che utilizzano i risultati dei modelli per produrre report, dati in input alle campagne e così via.
Concettualmente sia il flusso dei dati che la pila informatica sono molto semplici e non sono così diversi dagli schemi di tipo tradizionale, ai quali si affianca.

